Numpy基础
导入库函数
import numpy as np NumPy Ndarray 对象
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
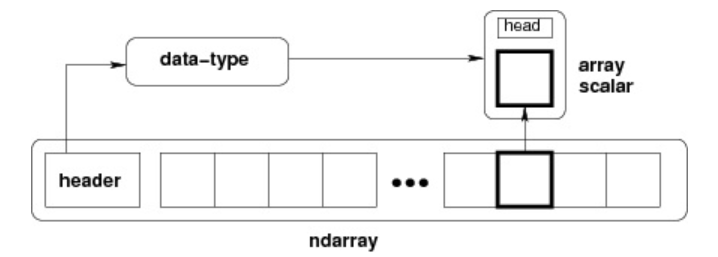
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)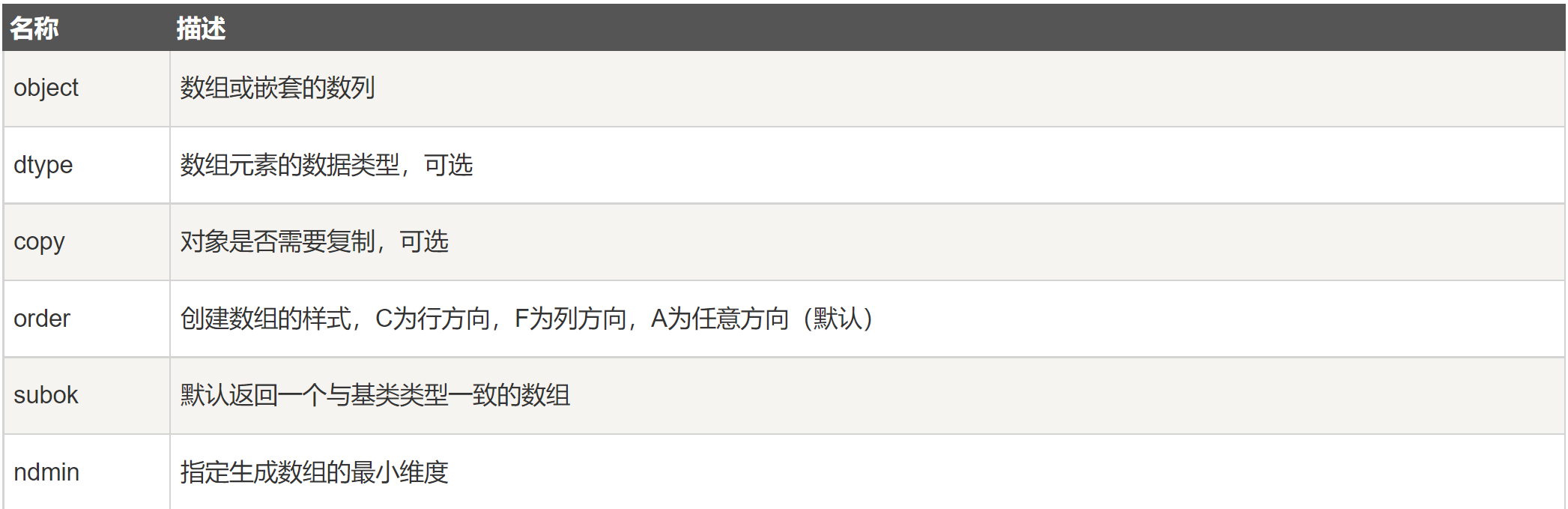
案例
import numpy as np
a = np.array([1,2,3])
a
# [1 2 3]import numpy as np
a = np.array([1, 2, 3, 4, 5], ndmin = 3)
a
#[[[1 2 3 4 5]]]import numpy as np
a = np.array([1, 2, 3], dtype = complex)
a
# array([1.+0.j, 2.+0.j, 3.+0.j])NumPy 数据类型

数据类型对象 (dtype)
numpy.dtype(object, align, copy)- object - 要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体。
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
字节顺序是通过对数据类型预先设定 < 或 > 来决定的。 < 意味着小端法(最小值存储在最小的地址,即低位组放在最前面)。> 意味着大端法(最重要的字节存储在最小的地址,即高位组放在最前面)。
案例
import numpy as np
dt = np.dtype(np.int32)
dt
# dtype('int32')import numpy as np
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
dt = np.dtype('i4')
dt
# dtype('int32')import numpy as np
# 字节顺序标注
dt = np.dtype('<i4')
dt
# dtype('int32')import numpy as np
# 创建结构化数据类型
dt = np.dtype([('age',np.int8)])
dt
# dtype([('age', 'i1')])# 将数据类型应用于 ndarray 对象
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
# array([(10,), (20,), (30,)], dtype=[('age', 'i1')])
# # 类型字段名可以用于存取实际的 age 列
a['age']
# array([10, 20, 30], dtype=int8)定义一个结构化数据类型 student,包含字符串字段 name,整数字段 age,及浮点字段 marks,并将这个 dtype 应用到 ndarray 对象。
dt = np.dtype([('name','S10'),('age','i8'),('class_id','i8')])
a = np.array([('a',16,1),('b',17,2),('c',18,3)],dtype = dt)
a
# array([(b'a', 16, 1), (b'b', 17, 2), (b'c', 18, 3)],
# dtype=[('name', 'S10'), ('age', '<i8'), ('class_id', '<i8')])
NumPy 数组属性
知识点
- NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
- 每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
- 很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。

案例
# 转置改变维数 ndarray.ndim
import numpy as np
a = np.arange(24)
print (a.ndim)
b = a.reshape(2,4,3)
print (b.ndim)
# 1
# 3# 调整数组大小 ndarray.shape
a = np.array([[1,2,3],[4,5,6]])
print (a.shape)
# (2, 3)
a.shape = (3,2)
print(a)
#[[1 2]
# [3 4]
# [5 6]]
#reshape函数也可以调整数组大小
a = a.reshape(2,3)
a
# array([[1, 2, 3],
# [4, 5, 6]])# 以字节形式返回每个元素大小 ndarray.itemsize
# 数组的 dtype 为 int8(一个字节)
x = np.array([1,2,3,4,5], dtype = np.int8)
print (x.itemsize)
# 数组的 dtype 现在为 float64(八个字节)
y = np.array([1,2,3,4,5], dtype = np.float64)
print (y.itemsize)
# 1
# 8# 返回 ndarray 对象的内存信息 ndarray.flags
x = np.array([1,2,3,4,5])
print (x.flags)
# C_CONTIGUOUS : True
# F_CONTIGUOUS : True
# OWNDATA : True
# WRITEABLE : True
# ALIGNED : True
# WRITEBACKIFCOPY : False
# UPDATEIFCOPY : False
NumPy 创建数组
numpy.empty
numpy.empty(shape, dtype = float, order = 'C')
实例
import numpy as np
x = np.empty([3,2], dtype = int)
print (x)
# [[ 0 1072693248]
# [ 0 1073741824]
# [ 0 1074266112]]numpy.zeros
创建指定大小的数组,数组元素以 0 来填充
numpy.zeros(shape, dtype = float, order = 'C')
实例
# 默认为浮点数
x = np.zeros(5)
print(x)
# 设置类型为整数
y = np.zeros((5,), dtype = int)
print(y)
# 自定义类型
z = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print(z)
# [0. 0. 0. 0. 0.]
# [0 0 0 0 0]
# [[(0, 0) (0, 0)]
# [(0, 0) (0, 0)]]numpy.ones
创建指定形状的数组,数组元素以 1 来填充
numpy.ones(shape, dtype = None, order = 'C')
实例
# 默认为浮点数
x = np.ones(5)
print(x)
# 自定义类型
x = np.ones([2,2], dtype = int)
print(x)
# [1. 1. 1. 1. 1.]
# [[1 1]
# [1 1]]NumPy 从已有的数组创建数组
numpy.asarray()
numpy.asarray(a, dtype = None, order = None)- a --> 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组
- dtype -->数据类型
- order --> 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
实例
# 将列表转换为 ndarray
import numpy as np
x = [1,2,3]
a = np.asarray(x)
a
# [1 2 3]# 将元组转换为 ndarray
x = (1,2,3)
a = np.asarray(x)
a
# array([1, 2, 3])# 将元组列表转换为 ndarray
x = [(1,2,3),(4,5)]
a = np.asarray(x)
a
# array([(1, 2, 3), (4, 5)], dtype=object)# 设置了 dtype 参数
x = [1,2,3]
a = np.asarray(x, dtype = float)
anumpy.frombuffer
numpy.frombuffer 用于实现动态数组。
numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)注意: buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b。
buffer可以是任意对象,会以流的形式读入。dtype返回数组的数据类型,可选count读取的数据数量,默认为-1,读取所有数据offset读取的起始位置,默认为0
实例
import numpy as np
s = b'Hello World'
a = np.frombuffer(s, dtype = 'S1')
a
# array([b'H', b'e', b'l', b'l', b'o', b' ', b'W', b'o', b'r', b'l', b'd'],dtype='|S1')numpy.fromiter
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.fromiter(iterable, dtype, count=-1)iterable可迭代对象dtype返回数组的数据类型count读取的数据数量,默认为-1,读取所有数据
import numpy as np
# 使用 range 函数创建列表对象
list=range(5)
it=iter(list)
# 使用迭代器创建 ndarray
x=np.fromiter(it, dtype=float)
x
# array([0., 1., 2., 3., 4.])NumPy 从数值范围创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象
numpy.arange(start, stop, step, dtype)实例
# 生成 0 到 5 的数组
import numpy as np
x = np.arange(5)
x
# array([0, 1, 2, 3, 4])x = np.arange(5, dtype = float)
x
array([0., 1., 2., 3., 4.])# 设置了起始值、终止值及步长
x = np.arange(10,20,2)
x
# array([10, 12, 14, 16, 18])numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)start序列的起始值stop序列的终止值,如果endpoint为true,该值包含于数列中num要生成的等步长的样本数量,默认为50endpoint该值为true时,数列中包含stop值,反之不包含,默认是Trueretstep如果为 True 时,生成的数组中会显示间距,反之不显示dtypendarray的数据类型
实例
import numpy as np
a = np.linspace(1,10,10)
a
# array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])# 将 endpoint 设为 false,不包含终止值:
a = np.linspace(10, 20, 5, endpoint = False)
a
# array([10., 12., 14., 16., 18.])# 设置间距
import numpy as np
a =np.linspace(1,10,10,retstep= True)
a
# (array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]), 1.0)
# 拓展例子
b =np.linspace(1,10,10).reshape([10,1])
b
# array([[ 1.],
# [ 2.],
# [ 3.],
# [ 4.],
# [ 5.],
# [ 6.],
# [ 7.],
# [ 8.],
# [ 9.],
# [10.]])numpy.logspace
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)-
start序列的起始值为:base ** start -
stop序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中 -
num要生成的等步长的样本数量,默认为50 -
endpoint该值为true时,数列中中包含stop值,反之不包含,默认是True -
base对数 log 的底数 -
dtypendarray的数据类型
实例
import numpy as np
# 默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
a
# array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
# 27.82559402, 35.93813664, 46.41588834, 59.94842503,
# 77.42636827, 100. ])# 将底数设置为2
a = np.logspace(0,9,10,base=2)
a
# array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])NumPy 切片和索引
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
# 下面这种表达一样可以进行切片
# b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
a[s]
# array([2, 4, 6])冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
a[...,1]
# 第2列元素 array([2, 4, 5])
a[1,...]
# 第2行元素 array([3, 4, 5])
a[...,1:]
# 第2列及剩下的所有元素 array([4, 5, 6])

